A Very-Low Delay High-Performance Speech Vocoder Based on the Encodec Speech Decoder
Authors: Renzheng Shi, Tim Fingscheidt
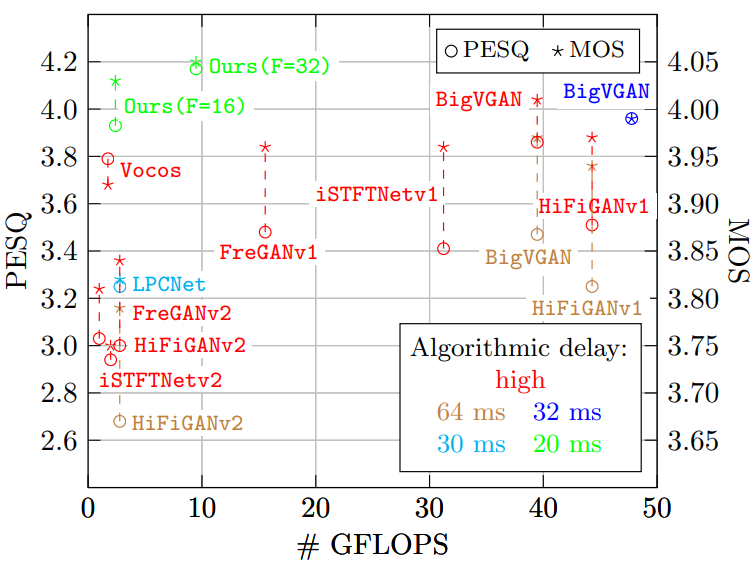
Neural vocoders demonstrated superior synthesized speech quality. However, their sequence-to-sequence synthesis prohibits low-latency conversational applications. Introducing causal convolutions for low-delay synthesis often results in noticeable quality degradation. In our work, we propose a high-performance low-delay vocoder. First, we tailor the decoder of the advanced speech codec Encodec to a speech vocoder conditioned on Mel spectrogram input. Second, we investigate several topological changes to enhance the synthesized speech. Third, we leverage the large-scale training procedure from BigVGAN. In a speaker-independent wideband speech setup, our proposed low-delay vocoder achieves a subjective MOS score (by ITU-T P.808) of 4.05, excelling all investigated baselines in all quality metrics, while being computationally efficient and offering an only 20 ms algorithmic delay instead of sequence-to-sequence processing. Accordingly, our vocoder marks a new state of the art in its class.
Demos from VCTK
| Model | Alg. Delay | MOS | Female | Male | ||||
|---|---|---|---|---|---|---|---|---|
| p269 | p317 | p333 | p270 | p316 | p334 | |||
| Ground truth | - | 4.07 | ||||||
| HiFiGAN v1 | utternce-based | 3.97 | ||||||
| HiFiGAN v2 | utternce-based | 3.84 | ||||||
| FreGAN2 v1 | utternce-based | 3.96 | ||||||
| FreGAN2 v2 | utternce-based | 3.81 | ||||||
| iSTFTNet v1 | utternce-based | 3.96 | ||||||
| iSTFTNet v2 | utternce-based | 3.75 | ||||||
| BigVGAN base | utternce-based | 4.01 | ||||||
| Vocos | utternce-based | 3.92 | ||||||
| LPCNet | 30 ms | 3.82 | ||||||
| Modified causal BigVGAN | 32 ms | 3.99 | ||||||
| Ours, F16 | 20 ms | 4.03 | ||||||
| Ours, F32 | 20 ms | 4.05 | ||||||